Scalability
All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirection.
--David Wheeler
- When our application becomes famous, to accommodate large volume of visits, we need to scale up (in application or database layer). Scalability includes vertical and horizontal ones.
- In vertical, we can increase the computation capability or storage of our server. But when the scale exceeds the capability of single machine, we will need the horizontal scalability;
- In horizontal, we increase the number of machines, where replication, sharding and load balancing may be involved.
- Replication: We can replicate data onto several database, so that incoming query can fetch data from oen of these databases; or we can have several servers, where all of them will apply the same logic.
- Sharding: sharding is like partitioning data into parts, i.e. by prefix or some characteristics, so that traffic flow can be divided and lessened on single machine.
- Then how does client know which machine to visit?
- A simple solution is with DNS server, and the server will provide different IP address for different clients, for example, in Round Robin manner, or based on the user_id, or geo-location.
- The other way is using load balance, either with hardware or software implementation. The balancer will redirect traffic, based on load on different machine, or some characteristic of user (like when the incoming one is a super-user who will consume much computation capability). DNS server can be regarded as a simple load balancer acting in a random manner.
- So now, the client visit public IP address of load balancer, then LB redirects the traffic to one of the server/database private IP address. Load balancer will monitor different machines, listening to their heartbeat. When one of them is down, traffic will be directed to the others.
Fault tolerance
- By introducing load balancer, we can now handle more traffic. Also, we can have better fault tolerance using replication of machines. But this is not the end of story. What if the load balancer is down(single point failure)?
- Yes, we can also have several load balancers. When one LB is down, the others will take charge of his job, so the client won’t notice the difference. This is similar with the replication of LB.
- With several LB, now we need to consider the consistency of them (also for replication of machines):
- If we want data read from different databases to be the same, then we are trying to achieve consistency on database level. Based on the strictness of it, there are strong and weak consistency (which is also referred as eventual consistency).
- In eventual consistency, databases can communicate with each other with logs. So write on certain database will not need the lock on other databases, and will take effect later.
- If our application is read-heavy, we can assign one of them to be the ‘written’ machine. All writes will go to this machine, then broadcast to all other databases (with write-back or write-through policy).
- If we want the application server to store the session of client, but here client may visit different servers due to load balance, then we need to achieve the consistency between different visits. So that the same client will not need to input name and password everytime, and can proceed to cashier when buying things online.
- A simple solution is to direct the client to visit same server every time, based on the user ID or so on, so that the session can be stored on that server.
- A more sophisticated solution is to store the session in a center node, like load balancer. So server can check the session info on LB.
- If we want data read from different databases to be the same, then we are trying to achieve consistency on database level. Based on the strictness of it, there are strong and weak consistency (which is also referred as eventual consistency).
Consistent hashing
- Most of the NoSQL use key-value hash. The key can be hashed to numerical representation, then is stored. We can retrieve which node this entry is stored based on its hashcode. For example, if we have n databases, then we can do a modular on hashcode to decide which node to store.
- In the above case, when set of database changes, i.e. a new database comes, or one of them is down, we need to migrate data. For example, when n changes to n+1, each database needs to migrate 1/((n+1)*n) of its data, which in total is 1/(n+1). This is a big deal!
- Consistent hashing can solve the above problem. Considering the hash space as a cycle, and we position all the nodes onto that cycle. To store a new key-value pair, we find the nearest node in certain direction (clockwise or counter-clockwise), as illustrated by following figure[2].
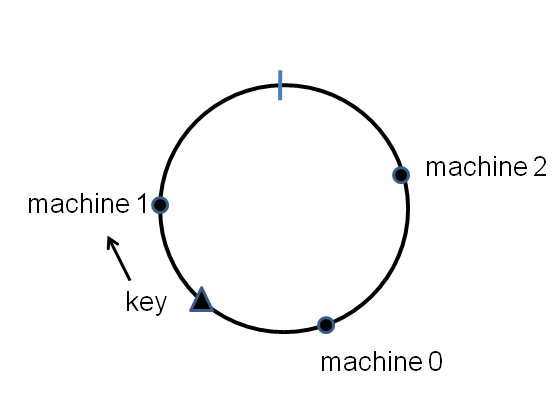
A cycle where points denote nodes, and the key will be stored in node 1.
- So when a new node comes, we insert that nodes onto the cycle. All data belong to the new node will be migrated. The portion of data migrated will be less than 1/n of all data, and it’s easier to choose the data to be migrated in this method.
- But it seems to be unfair to let the neighboring node of new node to do migration job. So here we can further divide node into r parts by inserting r duplicate notation onto the cycle. In total there will be nr points.
Other notes
- Winter is coming! It’s becoming colder and colder.