Hopefully another semester ends. I took an amazing course - ECE428 Distributed System this semester, and finished all 3 MPs with full scores. I wanna write down some of my thoughts when designing and implementing the MPs codes. I personally love to break down the complexity of a system, and build it with simple components. So lots of time are spent in designing before writting actual code.
MP1 - Distributed Fault-tolerant Totally Ordered Chatroom
- MP1 is building a totally ordered chatroom, which allows node failures. For totally ordered multicast, we use TCP sockets with ISIS algorithm. So there is no leader node or sequencer. For failure detection, we detect the state of node based on the TCP connection status, and change the member list when there is node change.
- Both of them (ISIS and failure detection) are easy to implement, but not when combined. The problem is there is a priority-queue in ISIS algo, where the message with small timestamp will halt at the front of queue, even when it can not be delivered yet. A message needs to receive suggested index from all available nodes, or confirmed index from initial sender, either case the sender may fail. Thus the message may be hindering other messages from delivery due to node change.
- The solution to that is by setting up a message-center thread, which acts as both the buffer and consumer. As shown in Fig 1, basically there are 3 threads that cooperate together. Node-change thread tackles node change, and change member list visible to message-center thread. Message-receive thread receive the messages, and change the messages info in message queue. The events in these two thread will affect the message-center thread. Then message-center thread wakes up for fixed time interval (50ms), check the message queue and member list, then deliver messages on top of queue continuously.
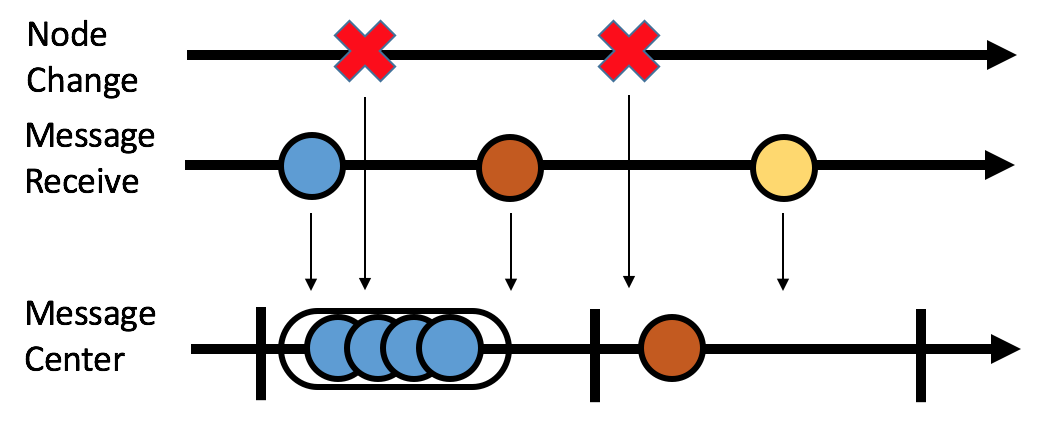
Fig 1. Thread relationship.
- To test the programs, we add network delay using tc like
sudo tc qdisc add dev eth0 root netem delay 100ms 50ms loss random 4
So there will be a delay of 100±50ms, and 4% of the packages are dropped. one lesson learned is when developing a project, we must test it on the real/production environment at each stage. We thought that the local environment will be similar with on the virtual machine, but only found that they behave much differently 2 days before demo when testing. Fortunately we debugged the code timely, but it were still 2-days hard work.
The overall structure is shown as below:
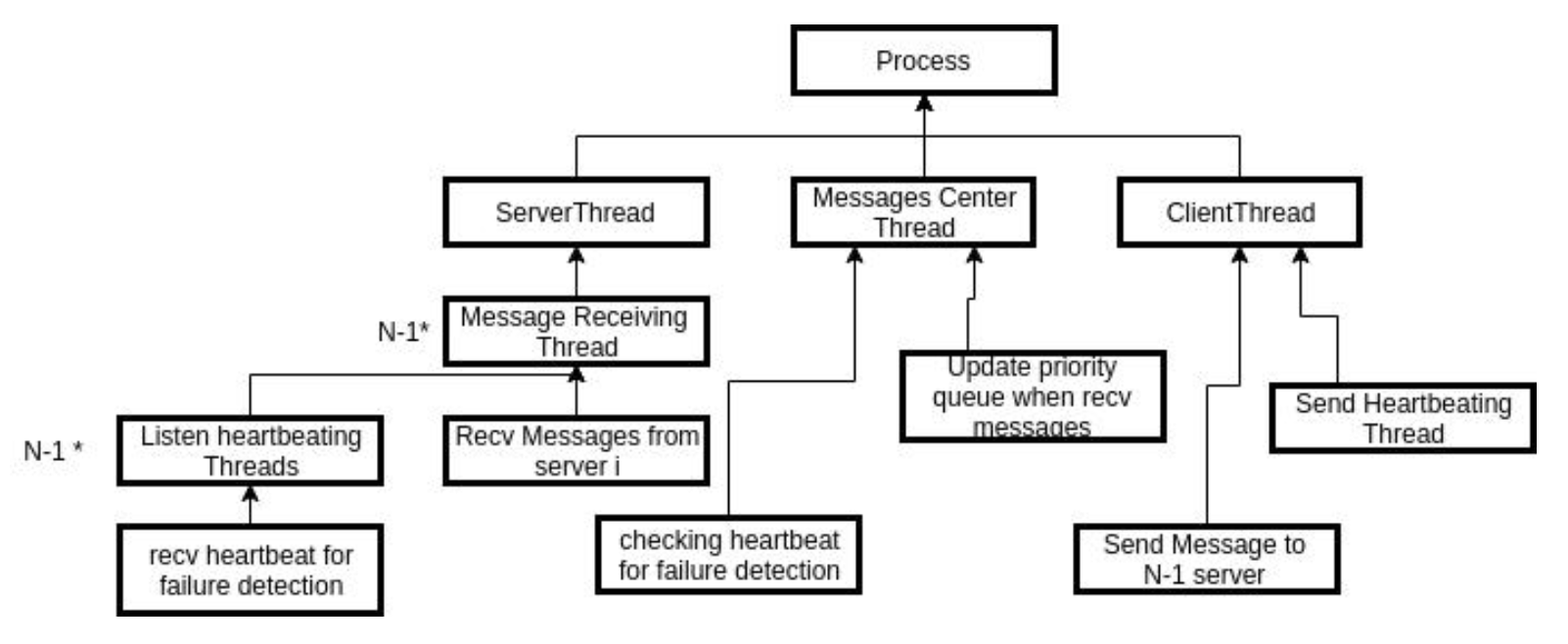
Fig 2. Program structure of MP1 code.
MP2 - Distributed Fault-tolerant Key-Value Store
- MP2 is building a fault-tolerant (at most 2 simultaneous failures) key-value store. We use DHT with consistent hashing, and 3-replica to tolerate failures. We assign the node on DHT as master node, and the predecessor and successor nodes as replicas.
- To ensure strong consistency (although the MP only requires eventual consistency), we direct all the read and write requests to master node, so that they can be serialized there. In addition, to avoid letting the message-receiving thread waiting for the callback, thus blocking the socket I/O, we use the producer-consumer model, where the message-receiving thread only needs to pre-process the coming request, then add it to the corresponding buffer, and receiving the next messages.
- For node change, we lock all the nodes when there is node join/failure. For node join, its neighboring node will pack-up the data and send them to the new node. For node failure, the available successor will beome the ‘responsible’ node of recovery, which transfer data to new replicas. Only after the responsible node multicast ‘unlock’ message can the other nodes unlock from lock state and proceed for new requests.
MP3 - Distributed Key-value Store Supporting Transaction
- MP3 is building a key-value store that supports transaction. That means, the transaction should be atomic, can receive intermediate result, support shared read lock and exclusive write lock, detect deadlock and is sequential equivalent. Besides the client nodes and server nodes (to store key-value pairs and respond to request), we have an additional node as coordinator.
- By using shared and exclusive lock in 2-phase-locking, we can easily support sequential equivalence of transaction. The main difficulty is the deadlock detection. A normal implementation is to register each lock acquired per object on coordinator, and check the cycle (to find deadlock) in object graph. When the number of requests increase in a transaction, the object graph will be pretty large. While accessing and modifying the graph will need a lock to prevent false positive of deadlock, the whole system will be very slow as a result.
- Well, if we analyze the problem, we can find that there is a deadlock only when there are ‘wait-for’ relationships between transaction. Each transaction will only register ‘wait-for’ once at a time (assume the transaction will pause there when waiting for others), but may have thousands of locks previous to that. So focusing on ‘wait-for’ relation of transaction can greatly reduce the complexity of the deadlock detection. Now we only need to check the cycle in ‘wait-for’ graph when a new ‘wait-for’ is registered, and this graph is much smaller, thus it is much faster to do so.
In a word, we learned a lot when developing these MPs. The most valuable lesson is always try to 'simplify' the system, which is easier to implement and debug, while leaving enough space for future expansion. The time spent on design is highly worthwhile!