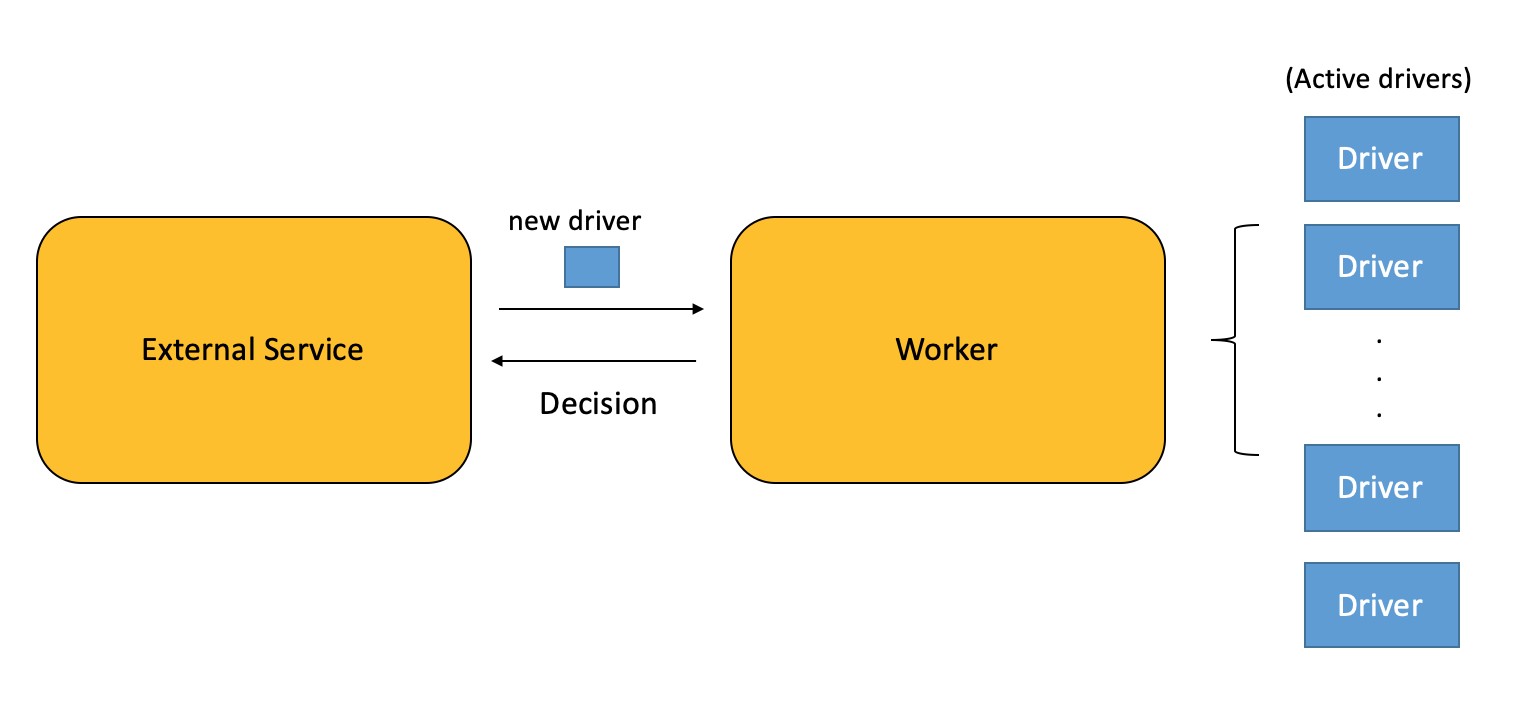
We have many different drivers to check every day. At first we check them manually, again and again.
我们组的平台每天需要审核很多的driver(硬件驱动更新),最开始我们用人工的方式不断循环审核。
Their amount increased quickly, and it exceeds our manual processing limit soon. Then let’s write a script to iterate them, and call external service API to make decision on driver.
随着数量不断增加,要审核的driver很快超出我们人工方式能承受的上限。于是我们开始用代码程序来逐步替代人工,call外部服务API来处理审核driver。
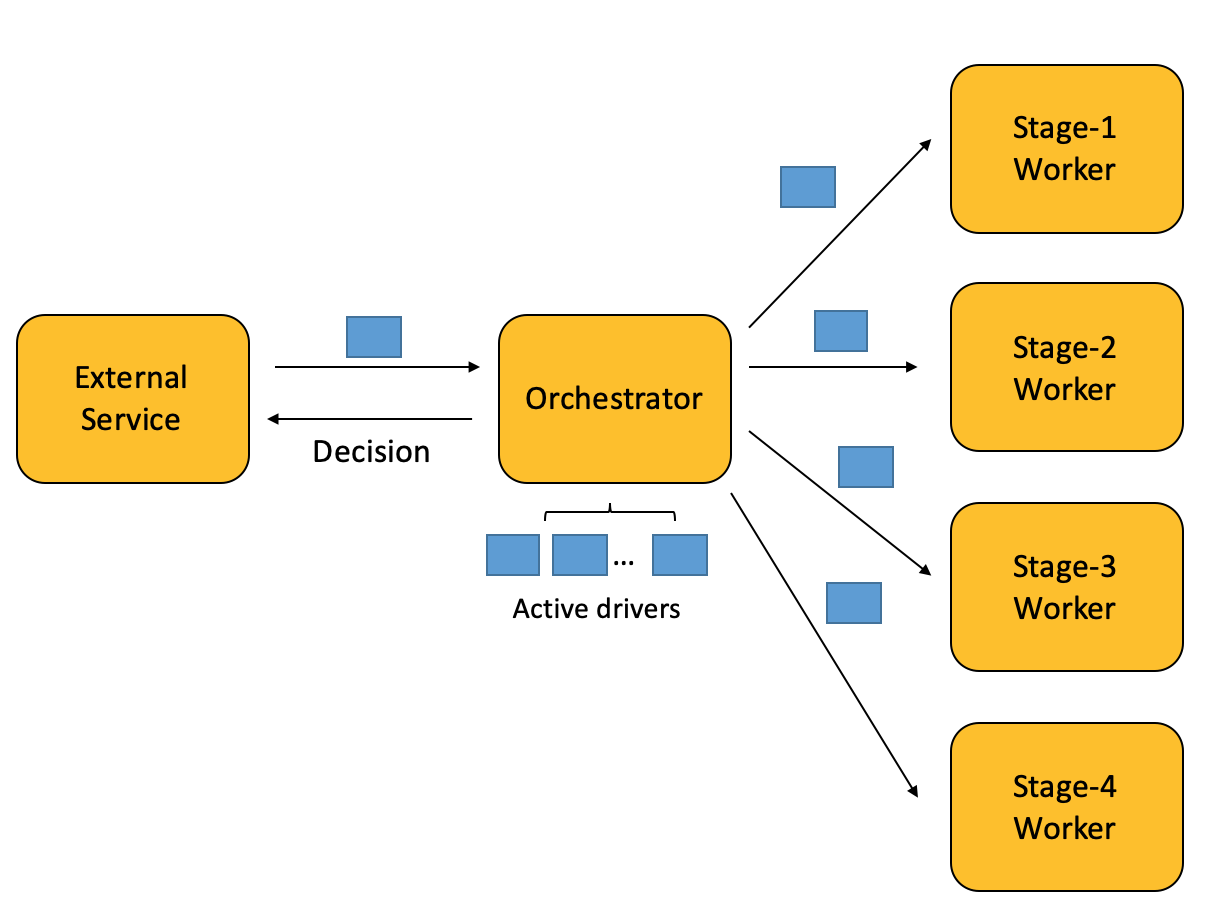
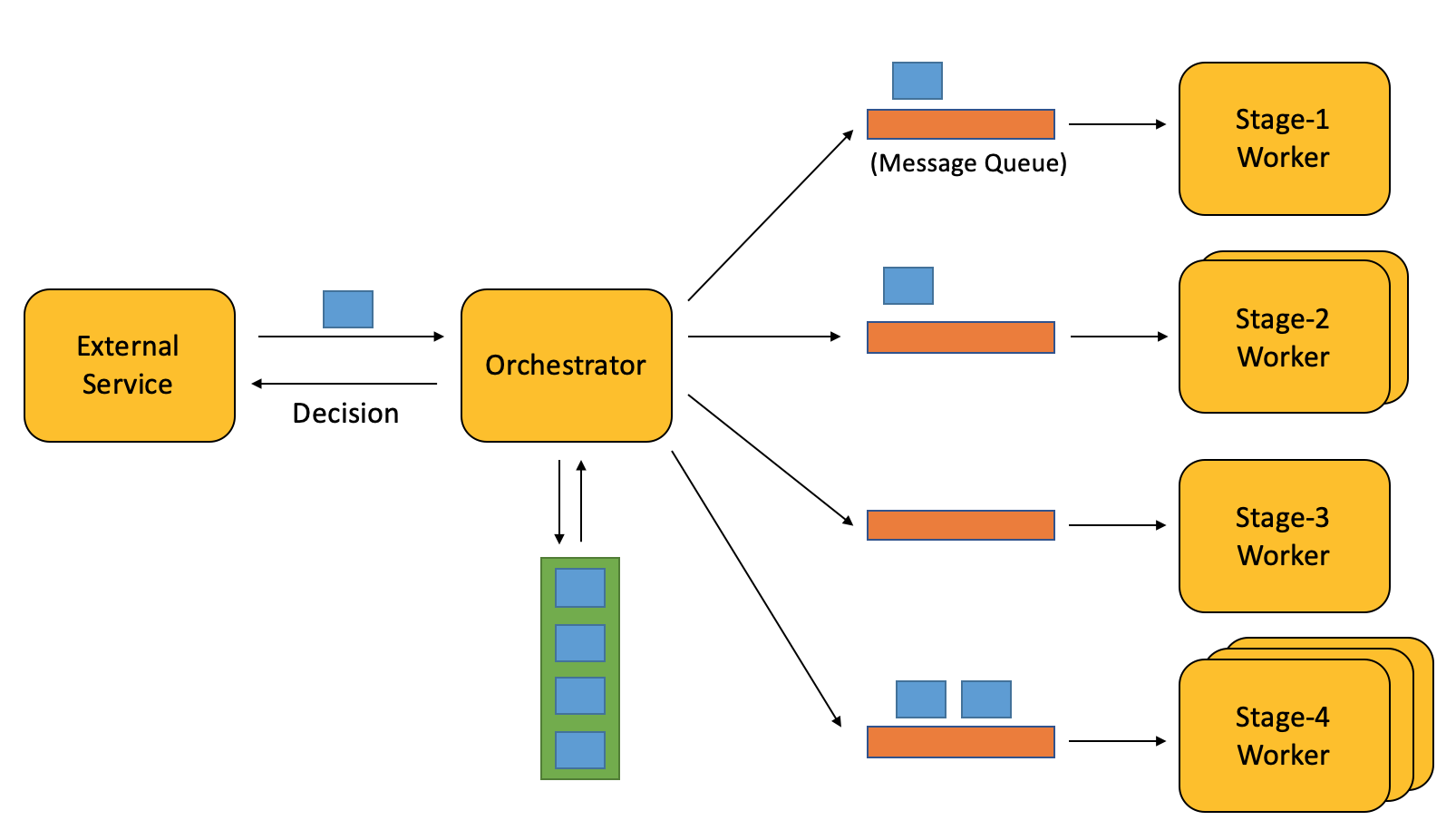
They may be at different stages, thus performing different sets of check. Let’s have different scripts for each stage, and add an Orchestrator to send driver to each script.
审核的内容可以分为不同阶段,每个阶段又分别会有不同的审核规则。于是我们按阶段区分程序,并让他们跑在不同的机子上,同时用一个Orchestrator(指挥者)程序来把不同按阶段driver分发到相应机子上。
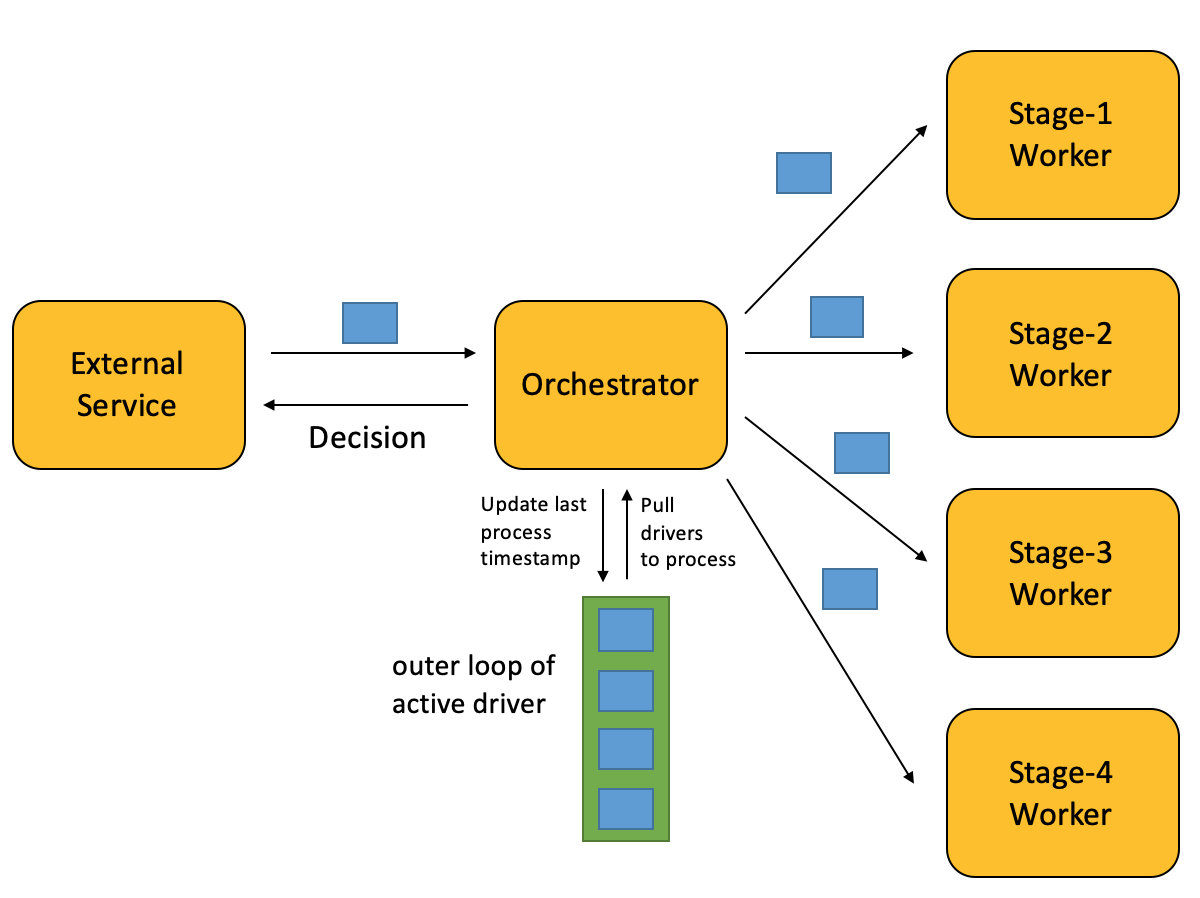
The orchestrator then becomes single-point-of-failure. If it shut down, we will need to traverse the list again (even if we have processed same driver recently). Let’s use an outer loop to record last timestamp we processed this driver, slice records into buckets (it does not hurt to process same driver twice) for each processing window (5 min), and process them iteratively.
这样指挥者会成为系统的单点故障:每当它因故障重启,我们都需要重新遍历所有需审核的driver(即使我们刚审核过同一个driver)。那么我们再用一个outer loop(ol列表)来记录上一次审核该driver的时间戳,并且把他们按每5分钟一批分批处理,不断循环(同一个driver被审核的频率不会对正确性造成影响,只要能在一定时间内有审核即可)。
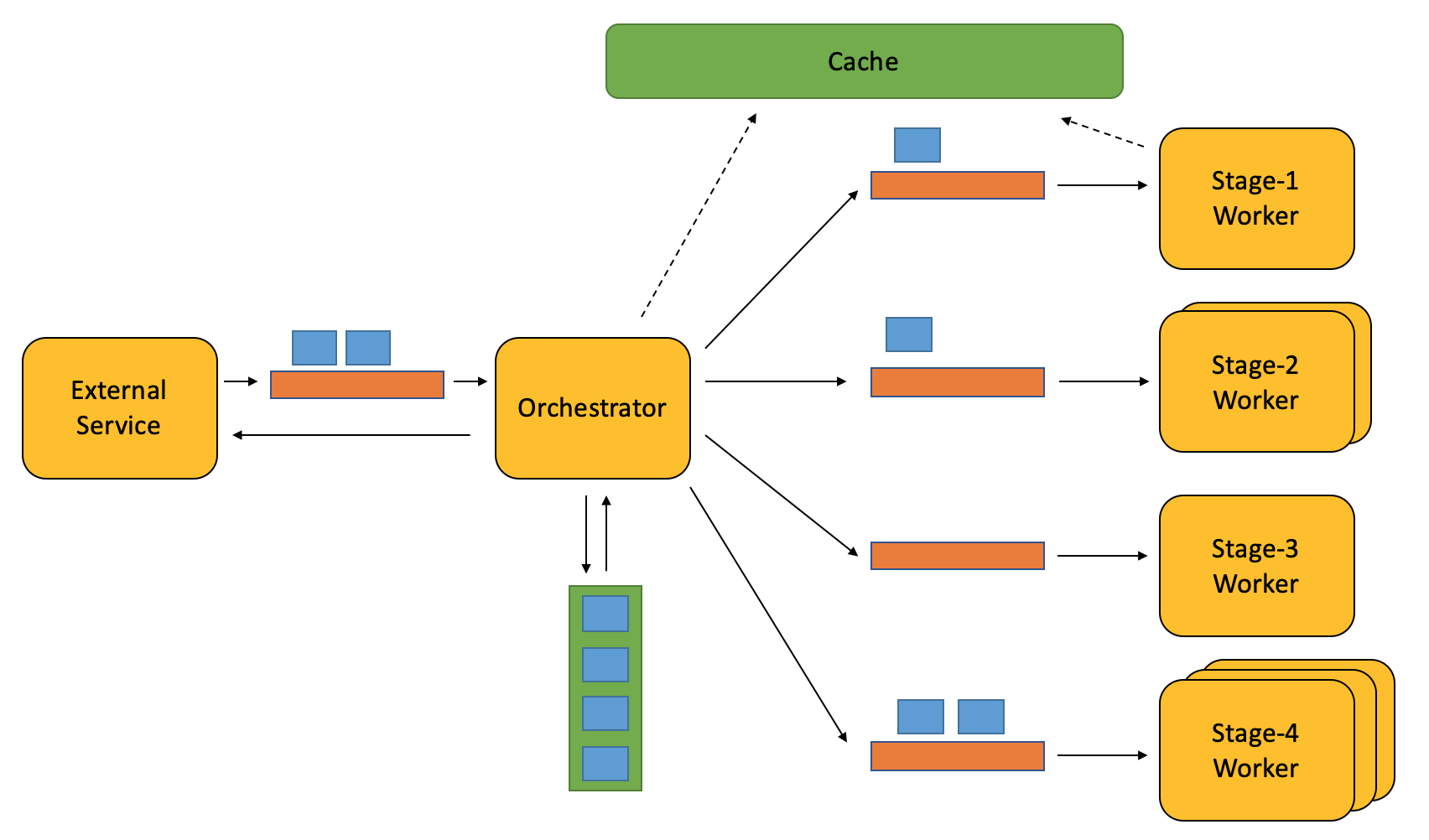
There may be too many drivers at certain stage, which causes Orchestrator to be stuck waiting for that stage’s worker to finish its work. Let’s use message queue to decouple them, so workers on consumer end can process when they are free (without Orchestrator waiting for their response), and we can scale out independently.
有的阶段的可能有过多的更新需审核,如果指挥者是用阻塞等待(指挥者会一直等待worker审核完所有发给它的更新,再进入下一个处理窗口),那会导致整个系统都因那个阶段而慢下来。于是我们用消息队列和消费者模型来解耦这两个组件,这样在消费者端的worker可以在它们有处理能力时立刻处理driver(而指挥者不用等他们的回复),也可以更容易水平扩容处理能力。
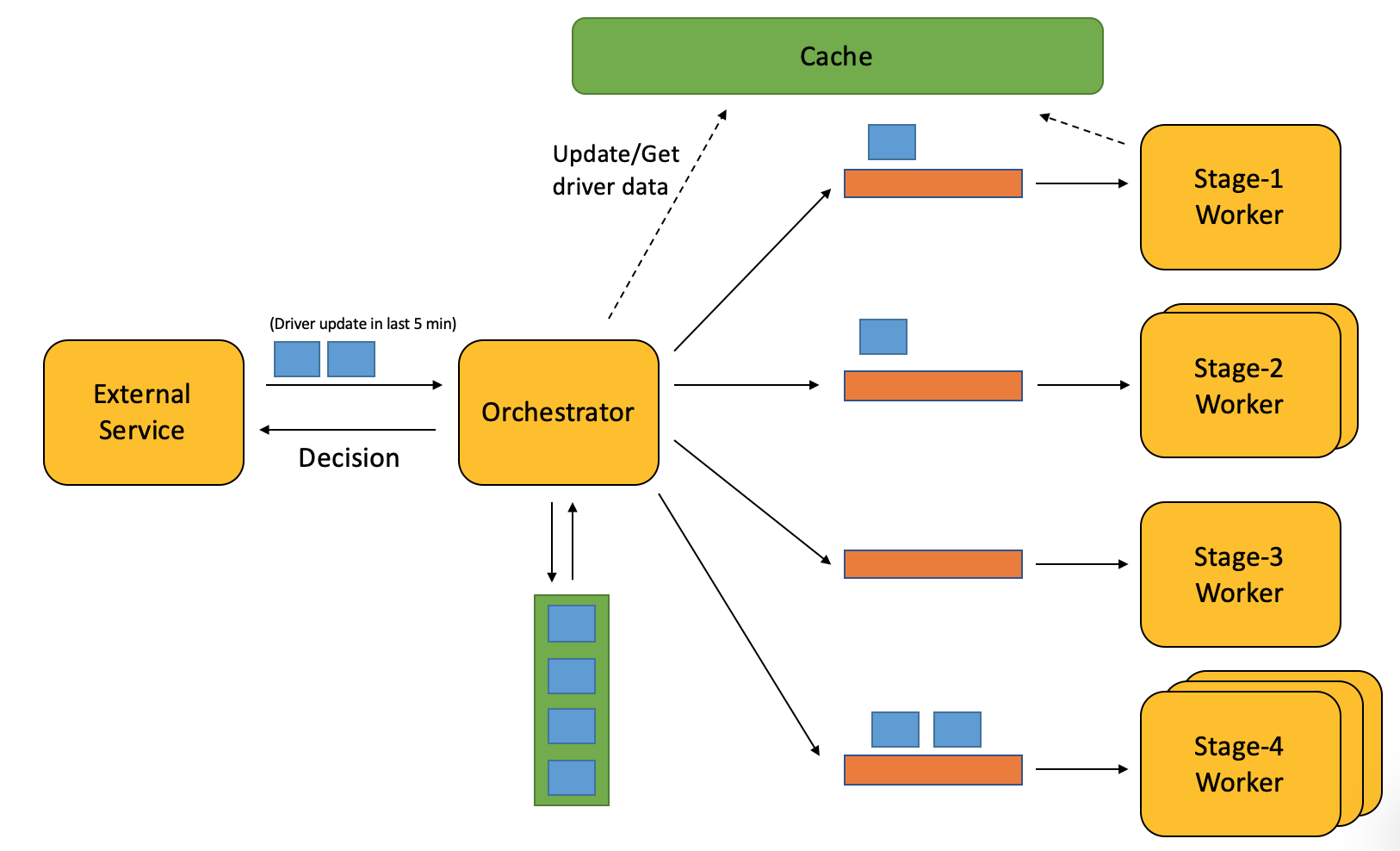
One more issue is, we pull current data of the driver (from external service) each time before processing, but many of them actually don’t change frequently. Thus we put a cache of their data in out system, so we don’t need to pull driver without any changes. All we need is to ask (the external service) what drivers have update in last 5 min window.
还有一个问题是,每次在处理driver之前,我们都会去外部服务获取driver最新的相关信息,但其实这些信息变化的频率不是很高。于是我们在系统里加了driver信息的缓存,这样如果driver没有变化的话,我们就只会从缓存去拿信息,而不用再去询问外部服务。为了知道有哪些driver有变化,我们每5分钟询问外部服务在过去5分钟里,哪些driver需要更新。
They (external service) can also just ping us when there is update on a driver, and we process immediately.
外部服务也可以每当driver有变化时就ping我们,然后我们立刻更新缓存并处理此driver。
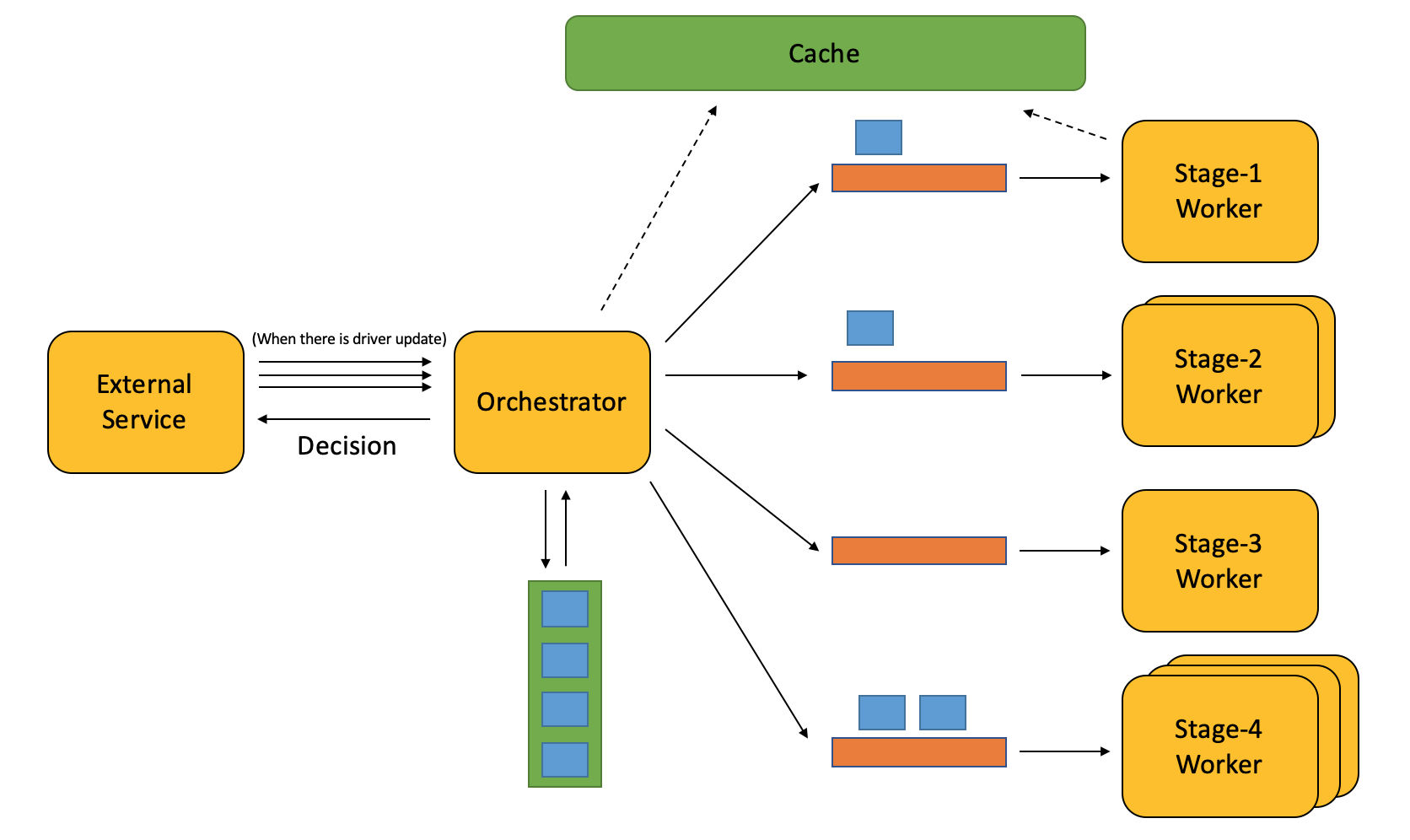
Still there can be too many driver updates, let’s also use a message queue in between, so Orchestrator can process at its pace.
但这样的坏处是当某个时段driver变化比较集中,会给系统带来很大处理压力。于是我们和外部服务中间加了一个消息队列解耦,并削峰填谷,减轻指挥者对driver更新的并发处理压力。